2024 Conference
Announcing the NeurIPS 2024 Best Paper Awards
Announcing the NeurIPS 2024 Best Paper Awards
By Marco Cuturi, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub Tomczak, Cheng Zhang, Lora Aroyo, Francesco Locatello, Lingjuan Lyu
The search committees for the “Best Paper Award” were nominated by the program chairs and the respective track chairs, who selected leading researchers with a diverse perspective on machine learning topics. These nominations were approved by the general and DIA chairs.
The best paper award committees were tasked with selecting a handful of highly impactful papers from both tracks of the conference. The search committees considered all accepted NeurIPS papers equally, and made decisions independently based on the scientific merit of the papers, without making separate considerations on authorship or other factors, in keeping with the Neurips blind review process.
With that, we are excited to share the news that the best and runner up paper awards this year go to five ground-breaking papers (four main track and one datasets and benchmarks track) that highlight, respectively, a new autoregressive model for vision, new avenues for supervised learning using higher-order derivatives, improved training of LLMs and inference methods for text2image diffusion and a novel diverse benchmark dataset for LLM alignment.
Best papers for the main track:
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
This paper introduces a novel visual autoregressive (VAR) model that iteratively predicts the image at a next higher resolution, rather than a different patch in the image following an arbitrary ordering. The VAR model shows strong results in image generation, outperforming existing autoregressive models in efficiency and achieving competitive results with diffusion-based methods. At the core of this contribution lies an innovative multiscale VQ-VAE implementation. The overall quality of the paper presentation, experimental validation and insights (scaling laws) give compelling reasons to experiment with this model.
Stochastic Taylor Derivative Estimator: Efficient amortization for arbitrary differential operators
This paper proposes a tractable approach to train neural networks (NN) using supervision that incorporates higher-order derivatives. Such problems arise when training physics-informed NN to fit certain PDEs. Naive application of automatic differentiation rules are both inefficient and intractable in practice for higher orders k and high dimensions d. While these costs can be mitigated independently (e.g. for large k but small d, or large d but small k using subsampling) this paper proposes a method, stochastic taylor derivative estimator (STDE) that can address both. This work opens up possibilities in scientific applications of NN and more generally in supervised training of NN using higher-order derivatives.
Runners ups for the main track:
Not All Tokens Are What You Need for Pretraining
This paper presents a simple method to filter pre-training data when training large language models (LLM). The method builds on the availability of a high-quality reference dataset on which a reference language model is trained. That model is then used to assign a quality score for tokens that come from a larger pre-training corpus. Tokens whose scores have the highest rank are then used to guide the final LLM training, while the others are discarded. This ensures that the final LLM is trained on a higher quality dataset that is well aligned with the reference dataset.
Guiding a Diffusion Model with a Bad Version of Itself
This paper proposes an alternative to classifier free guidance (CFG) in the context of text-2-image (T2I) models. CFG is a guidance technique (a correction in diffusion trajectories) that is extensively used by practitioners to obtain better prompt alignment and higher-quality images. However, because CFG uses an unconditional term that is independent from the text prompt, CFG has been empirically observed to reduce diversity of image generation. The paper proposes to replace CFG by Autoguidance, which uses a noisier, less well-trained T2I diffusion model. This change leads to notable improvements in diversity and image quality.
Best paper for Datasets & Benchmarks track:
Alignment of LLMs with human feedback is one of the most impactful research areas of today, with key challenges such as confounding by different preferences, values, or beliefs. This paper introduces the PRISM dataset providing a unique perspective on human interactions with LLMs. The authors collected data from 75 countries with diverse demographics and sourced both subjective and multicultural perspectives benchmarking over 20 current state of the art models. The paper has high societal value and enables research on pluralism and disagreements in RLHF.
Best Paper Award committee for main track: Marco Cuturi (Committee Lead), Zeynep Akata, Kim Branson, Shakir Mohamed, Remi Munos, Jie Tang, Richard Zemel, Luke Zettlemoyer
Best Paper Award committee for dataset and benchmark track: Yulia Gel, Ludwig Schmidt, Elena Simperl, Joaquin Vanschoren, Xing Xie.
Results of the NeurIPS 2024 Experiment on the Usefulness of LLMs as an Author Checklist Assistant for Scientific Papers
Large language models (LLMs) represent a promising but controversial aide in the process of preparing and reviewing scientific papers. Despite risks like inaccuracy and bias, LLMs are already being used in the review of scientific papers. [1,2] Their use raises the pressing question: “How can we harness LLMs responsibly and effectively in the application of conference peer review?”
In an experiment at this year’s NeurIPS, we took an initial step towards answering this question. We evaluated a relatively clear-cut and low-risk use case: vetting paper submissions against submission standards, with results shown only to paper authors. We deployed an optional to use LLM-based “Checklist Assistant” to authors at NeurIPS 2024 as an assistant to check compliance with the NeurIPS Paper Checklist. We then systematically evaluated the benefits and risks of the LLM Checklist Assistant focusing on two main questions:
(1) Do authors perceive an LLM Author Checklist Assistant as a valuable enhancement to the paper submission process?
(2) Does the use of an Author Checklist Assistant meaningfully help authors to improve their paper submissions?
While there are nuances to our results, the main takeaway is that an LLM Checklist Assistant can effectively aid authors in ensuring scientific rigor, but should likely not be used as a fully automated review tool that replaces human review.

Example of checklist questions, answers, and LLM-provided review from the Checklist Assistant.
(1) Did authors find the Checklist Assistant useful?
We administered surveys both before and after use of the Checklist Assistant asking authors about their expectations for and perceptions of the tool. We received 539 responses to the pre-usage survey, 234 submissions to the Checklist Assistant and 78 responses to the post-usage survey.
Authors felt the Checklist Assistant was a valuable enhancement to the paper submission process. The majority of surveyed authors reported a positive experience using the LLM Checklist Assistant: >70% of authors found it useful and >70% said they would modify their paper in response to feedback.
Interestingly, authors’ expectations of the assistant’s effectiveness were even more positive before using it than their assessments after actually using it. Comparing pre- and post-usage responses, there was a statistically significant drop in positive feedback on the “Useful” and “Excited to Use” questions.
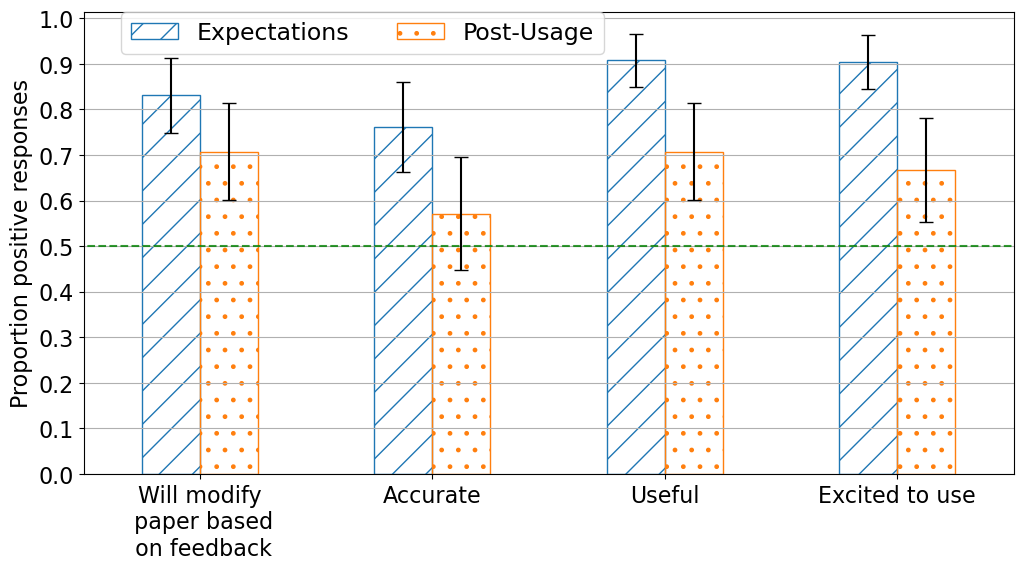
Responses to survey questions before and after using checklist verification (n=63 unique responses.)
(2) What were the main issues authors had with the Checklist Assistant?
We also solicited freeform feedback on issues that the authors experienced using the Checklist Assistant, with responses grouped below.
Among the main issues reported by authors in qualitative feedback, the most frequently cited problems were inaccuracy (20/52 respondents) and that the LLM was too strict in its requirements (14/52 respondents).
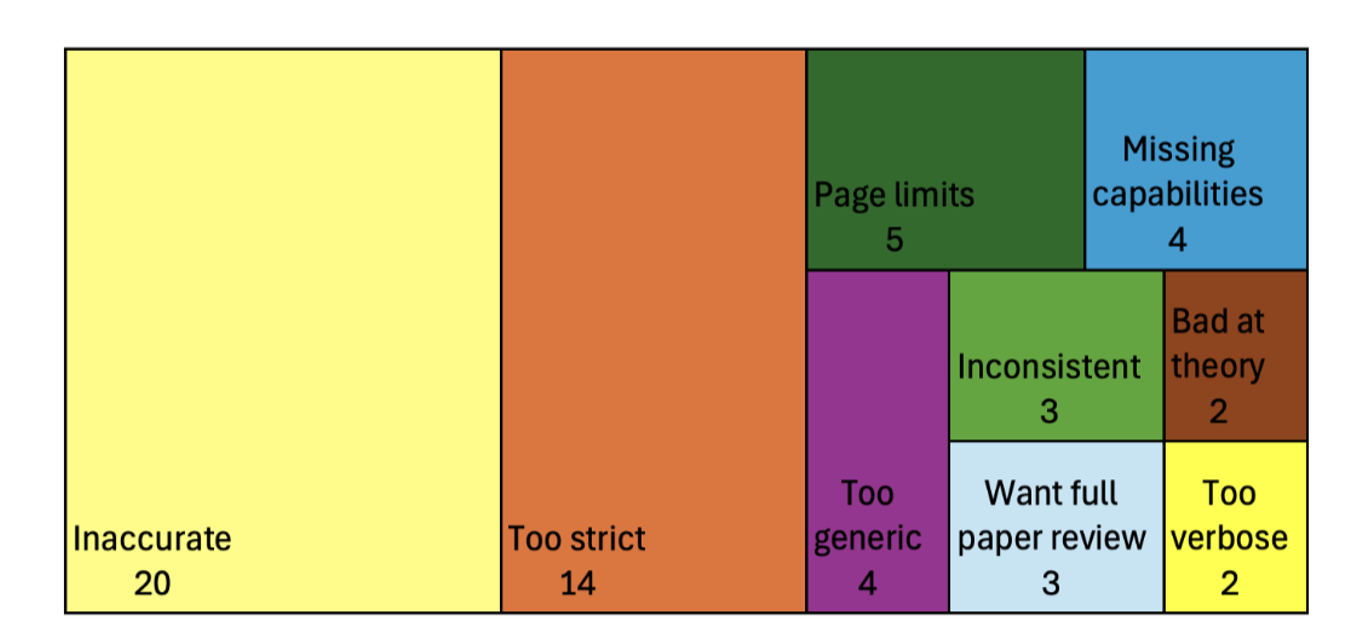
Reported issues using checklist verification from freeform feedback on post-usage survey (n=52 out of 78 total survey responses.)
(3) What kinds of feedback did the Checklist Assistant provide?
We used another LLM to extract key points from the Checklist Assistant’s responses for each question on the paper checklist and to cluster these points into overarching categories. Below we show the most frequent categories of feedback given by the Author Checklist Assistant on four questions of the checklist:
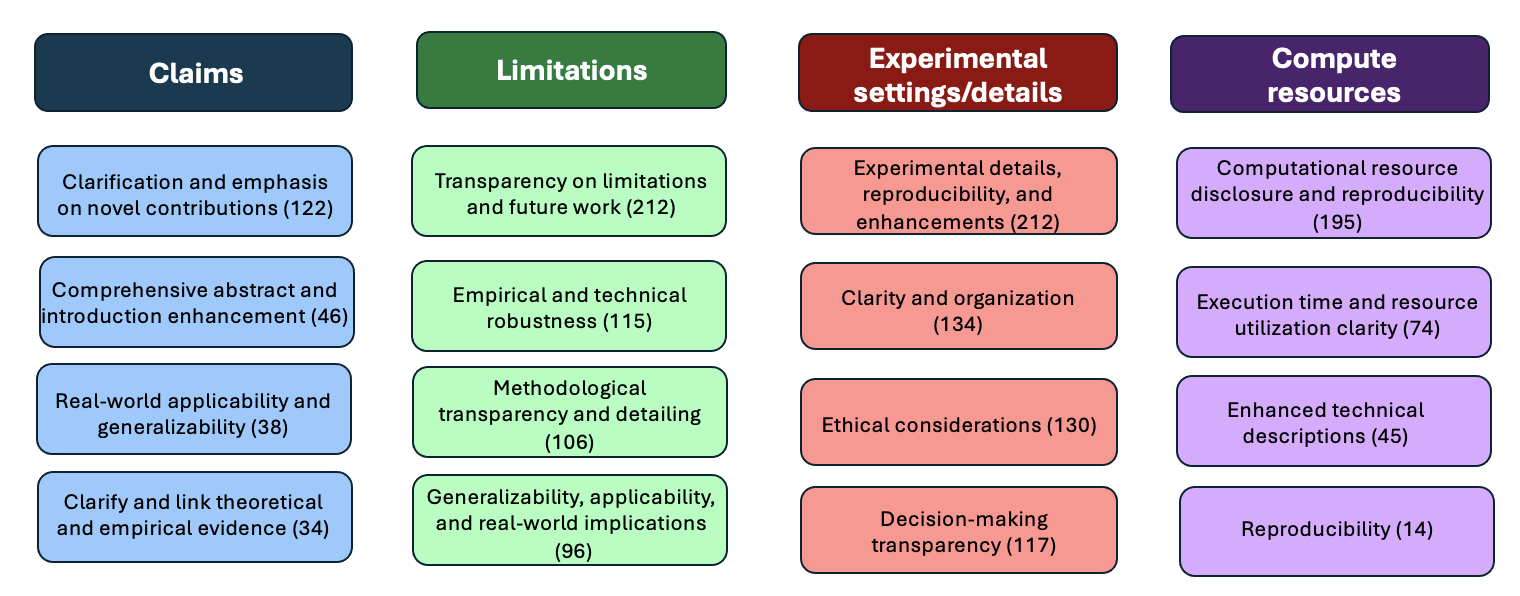
Clustering of most common types of feedback given by the LLM Checklist Assistant on four checklist questions.
The LLM was able to give concrete feedback to authors grounded in the content of their paper and checklist. The LLM tended to provide 4-6 distinct and specific points of feedback per question across the 15 questions. While it tended to give some generic boilerplate as part of its responses and to expand the scope of questions, it also was capable of giving concrete and specific feedback for many questions.
(4) Did authors actually modify their submissions?
Authors reported in freeform survey responses reflect that they planned to make meaningful changes to their submissions—35/78 survey respondents provided specific modifications they would make to their submissions in response to the Checklist Assistant. This included improving justifications for checklist answers and adding more details to the paper about experiments, datasets, or compute resources.
In 40 instances, authors submitted their paper twice to the checklist verifier (accounting for 80 total paper submissions.) We find that of the 40 pairs of papers, in 22 instances authors changed at least one answer in their checklist (e.g., ‘NA’ to ‘Yes’) between the first and second submission and in 39 instances they changed at least one justification for a checklist answer. Of the authors who changed justifications on their paper checklist, many authors made a large number of changes, with 35/39 changing more than 6 justifications of the 15 questions on the checklist. While we cannot causally attribute these changes to the Checklist Assistant, they suggest that authors may have incorporated feedback from the assistant in between submissions.
Below, we show (multiplicative) increase in word count between initial submission and final submission on questions where authors changed justifications (a value of 2 corresponds to a doubling of the length of an answer). We find that over half the time when authors changed a checklist answer, they more than doubled the length of their justification.
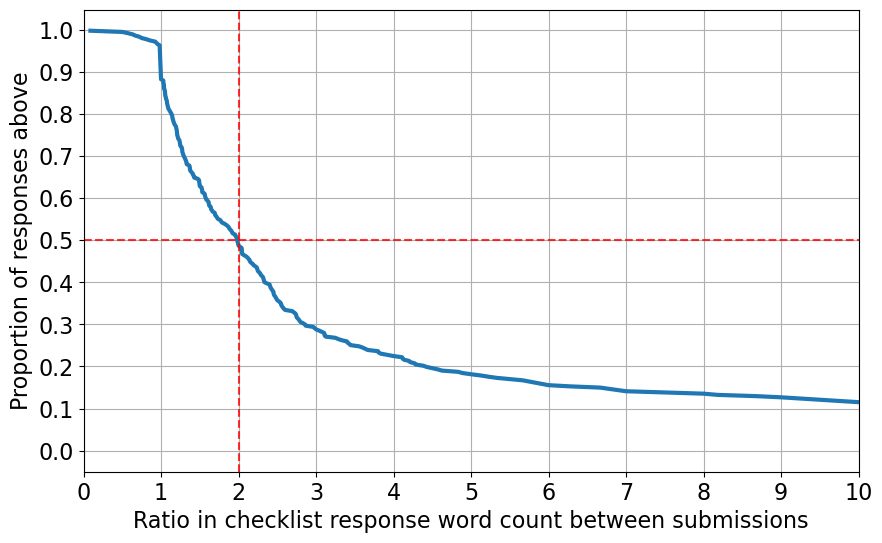
Change in word count of authors’ checklist responses between first and second submission to the Checklist Assistant. Over half the time, authors more than doubled the length of their checklist response.
In summary:
When authors submitted to the Checklist Assistant multiple times they almost always made changes to their checklists between submissions and significantly lengthened their answers, suggesting that they may have added content in response to LLM feedback.
(5) Can the Checklist Assistant be gamed?
The intended use of our Checklist Assistant was to help authors improve their papers, not to serve as a tool for reviewers to verify the accuracy of authors’ responses. If the system were used as an automated verification step as part of a review process, this could introduce an incentive for authors to “game” the system motivating the following question: could authors automatically improve the evaluations of their checklist responses with the help of AI, without making actual changes to their paper? If such gaming were possible, authors could provide a false impression of compliance to a conference without (much) additional effort and without actually improving their papers.
To assess whether our system is vulnerable to such gaming, we employed another LLM as an attack agent to iteratively manipulate the checklist justifications, aiming to deceive the Checklist Assistant. In this iterative process, the attack agent receives feedback from the system after each round and uses it to refine its justifications. We provided GPT-4o with the initial checklist responses and instructed it to revise the justifications based solely on feedback, without altering the underlying content of the paper. We allowed the attack agent to do this for three iterations (reflecting the submission limit on our deployed assistant), with the agent selecting the highest scored response for each checklist question over the iterations.
To statistically quantify how attack success we submitted the selected justification to our Checklist Assistant for an evaluation “Score” (1 when the Checklist Assistant said the checklist question had “No Issues” and 0 when the Assistant identified issues.) Below we show the results of this attack:
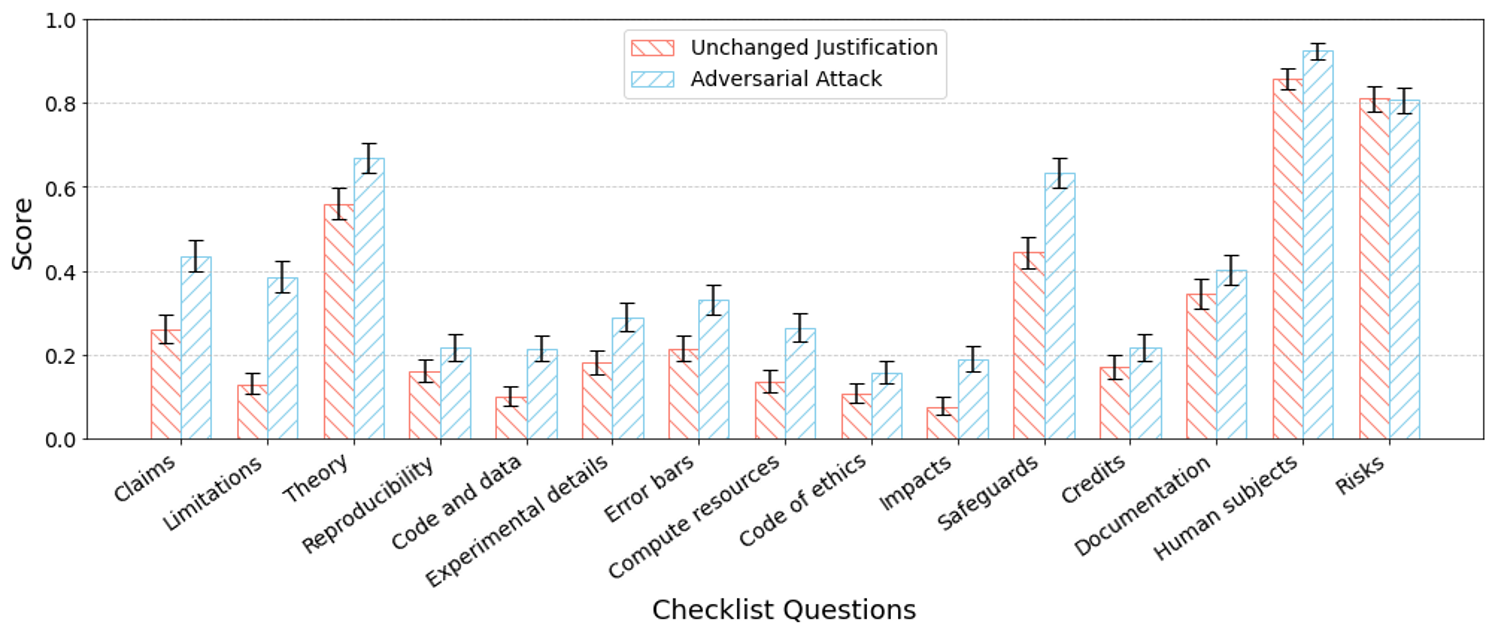
Authors could adversarially improve their chance of passing an automated LLM Checklist review by modifying their checklist without modifying their paper: on 14 out of 15 questions our simple adversarial attack shows a score increase when comparing the unchanged justifications with those refined through three iterations of automated improvement.
In a manual examination of the changes made by the (attacker) LLM to the justifications, we found that the attacker LLM employed several illegitimate strategies, such as adding a hardware description that was not present in the paper or original justifications and generating a placeholder URL as a purported repository for the code. These illegitimate justifications were evaluated as adequate by the Checklist Assistant.
Conclusions
Our deployment of an LLM-based paper Checklist Assistant at NeurIPS 2024 demonstrated that LLMs hold potential in enhancing the quality of scientific submissions by assisting authors in validating whether their papers meet submission standards. However, our study points to notable limitations in deploying LLMs within the scientific peer review process that need to be addressed, in particular accuracy and alignment issues. Further, our system was not robust to gaming by authors, suggesting that while a Checklist Assistant could be useful as an aid to authors it may be a poor substitute for human review. NeurIPS will continue to build on its LLM Policy Reviews for 2025.
For more details, see the full paper: https://arxiv.org/pdf/2411.03417.
For questions or suggestions, please contact us at: checklist@chalearn.org
[1] Liang et al., Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews, 2024. https://proceedings.mlr.press/v235/liang24b.html
[2] Latona et al., The AI Review Lottery: Widespread AI-Assisted Peer Reviews Boost Paper Scores and Acceptance Rates, 2024. https://arxiv.org/abs/2405.02150
Documentary Filming at NeurIPS 2024
72 Windfall Films will be filming at NeurIPS 2024 for a feature documentary about AI. This (filming) is a first-time experiment at NeurIPS, and any other filming is not permitted.
The team will be filming the poster sessions on the afternoon of Wednesday Dec 11, and they may also film a small number of other events (which we will also announce ahead of filming). The areas will be clearly marked with signs that contain the following info:
It is possible that you will be included in general shots of the conference. If you don’t want to appear in the programme, please contact Zara Powell at zara.powell@windfallfilms.com or +44 7557771061 immediately.
You can also find this info here: https://neurips.cc/Conferences/2024/FilmingNotice.
For any feedback about this filming, please contact the NeurIPS Communication Chairs at communication-chairs@neurips.cc.
NeurIPS2024 November Newsletter
Welcome to the November edition of the NeurIPS monthly Newsletter! NeurIPS2024 is around the corner. It will be held in Vancouver in less than a month, from Tuesday, Dec 10 to Sunday, Dec 15, 2024.
The NeurIPS Newsletter aims to provide an easy way to keep up to date with NeurIPS events and planning progress, respond to requests for feedback and participation, and find information about new initiatives.
You are receiving this newsletter as per your subscription preferences in your NeurIPS profile. As you prepare to attend NeurIPS, we hope that you will find the following information valuable. To unsubscribe from the NeurIPS newsletter, unselect the “Subscribe to Newsletter” checkbox in your profile: https://neurips.cc/Profile/subscribe. To update your email preference, visit: https://neurips.cc/FAQ/EmailPreferences
Newsletter includes:
- NeurIPS 2024 Conference Schedule
- NeurIPS 2024 Workshops
- NeurIPS 2024 Tutorials
- NeurIPS 2024 Affinity Events
- Bridging the Future Affinity Workshop
- NeurIPS Town Hall Details
- NeurIPS Highschool Projects Results
- Poster Printing Service
- Childcare and Other Amenities
- Reminder About Conference Dates
- NeurIPS EXPO
1) NeurIPS 2024 Conference Schedule
The details are posted on the conference website.
2) NeurIPS 2024 Workshops
NeurIPS 2024 workshops will take place on Dec. 14 & 15. We received 204 total submissions — a significant increase from last year. From this great batch of submissions, we have accepted 56 workshops. Given the exceptional quality of submissions this year, we wish we could have accepted many more, but we could not due to logistical constraints. We want to thank everyone who put in tremendous effort in submitting a workshop proposal. For a list of accepted workshops, refer to our blog post here.
3) NeurIPS 2024 Tutorials
The NeurIPS 2024 tutorials will be held on Tuesday, Dec 10. There will be 14 tutorials this year. All of them will be conducted in person to encourage active participation and some of them include panels to allow for a diverse range of discussion. For a list of accepted tutorials and their speakers, refer to our blog post here.
4) NeurIPS 2024 Affinity Events
We are excited to announce this year’s affinity events co-located with NeurIPS. At NeurIPS, affinity groups play a crucial role in promoting and supporting the ideas and voices of various communities that are defined by some axis of joint identity and raise awareness of issues that affect their members. In addition, they provide members of these affinity groups with increased opportunities to showcase their work, engage in discussions, and build connections during NeurIPS events, promoting diversity and inclusion at NeurIPS. For more information, please visit the Affinity Events Blog Post.
5) Bridging the Future
In this event, we will cover recent activities towards broadening participation activities in Artificial Intelligence and Machine Learning. NeurIPS has recently provided support to several groups active in this space, and in this event, they will describe their efforts and results. The event will take place on Thursday, December 12 at 7:30 pm in room East MR 18. Join us to learn about their ongoing project to better support their communities and the world. Light snacks and drinks will be served. See details here.
6) NeurIPS Town Hall Details
NeurIPS invites all attendees to our annual Town Hall, which will occur in person at the conference on Friday, December 13th at 7 PM this year. The NeurIPS Town Hall provides community members with an opportunity to hear updates and ask questions about the conference. The town hall lasts for an hour, with the first 30 minutes dedicated to presentations from various chairs and the last 30 minutes dedicated to an open Q&A from the community.
7) Announcing the NeurIPS High School Projects Results
We are thrilled to announce the results of the first call for NeurIPS High School Projects. With a theme of machine learning for social impact, this track was launched to get the next generation excited and thinking about how ML can benefit society, to encourage those already pursuing research on this topic, and to amplify that work through interaction with the NeurIPS community.
In total, we received 330 project submissions from high schoolers around the globe. Among those, 21 projects were chosen to be spotlighted and 4 were chosen as award winners. We congratulate all of the students and encourage community members to attend the joint poster session on Tuesday, December 10, where representatives of the four award-winning projects will present their work. For the details refer to this blog post.
8) Poster Printing Service
Read the NeurIPS poster printing information page for additional insight and information about templates, virtual poster and paper thumbnails, poster sizes, and printing.
You can use any service you want to print your poster. We offer an optional poster printing service.
9) Childcare and Other Amenities
NeurIPS is proud to provide free on-site child care. The deadline for registration has passed and it is now at capacity. We invite everyone to review the Child attendance policy here.
We kindly request that all attendees adhere to our child attendance policy by refraining from bringing children under the age of 14 to the venue unless they are registered in the childcare program.
Other amenities will include a nursing room and first aid.
10) Reminder About the Conference Dates
As already announced multiple times, the conference start date has been changed to Tuesday, December 10 in order to support delegates arriving on Monday for the Tuesday morning sessions. Registration will now open on Monday from 1 pm to 6 pm. Tutorials remain on Tuesday as originally scheduled. We encourage all attendees to verify dates directly on our website (https://neurips.cc/Conferences/2024) to avoid confusion.
11) NeurIPS EXPO
This year’s NeurIPS features an exciting lineup of 56 Expo events across December 10th-11th. This includes 18 interactive demonstrations on Tuesday, December 10th, along with 26 talk panels and 12 workshops spread across both days. Grab a coffee or box lunch and engage in an EXPO talk or workshop. Demos will be available on the exhibit sponsor hall floor.
Thanks and looking forward to seeing you at the conference.
Amir Globerson & Lester Mackey
NeurIPS 2024 General Chairs
Announcing the NeurIPS High School Projects Results
We are thrilled to announce the results of the first call for NeurIPS High School Projects. With a theme of machine learning for social impact, this track was launched to get the next generation excited and thinking about how ML can benefit society, to encourage those already pursuing research on this topic, and to amplify that work through interaction with the NeurIPS community.
In total, we received 330 project submissions from high schoolers around the globe. Among those, 21 projects were chosen to be spotlighted and 4 were chosen as award winners. We congratulate all of the students and encourage community members to attend the joint poster session on Tuesday December 10, where representatives of the four award-winning projects will present their work.
Award-winning Projects
ALLocate: A Low-Cost Automatic Artificial Intelligence System for the Real-Time Localization and Classification of Acute Myeloid Leukemia in Bone Marrow Smears
Ethan Yan, Groton School, MA, USA
Abstract: Accurate leukemia detection in current clinical practice remains challenging due to limitations in cost, time, and medical experience. To address this issue, this research develops the first integrated low-cost automatic artificial intelligence system for the real-time localization and classification of acute myeloid leukemia in bone marrow smears named ALLocate. This system consists of an automatic microscope scanner, an image sampling system, and a deep learning-based localization and classification system. A region classifier using a convolutional neural network (CNN) model was developed to select usable regions from unusable blood and clot regions. For real-time detection, the YOLOv8 model was developed and optimized. These models show high performance with a region classifier accuracy of 96% and YOLOv8 mAP of 91%. In addition, a low-cost automatic microscope scanner system was developed using 3D-printed pieces controlled by stepper motors and a programmed Arduino-based RAMPS control board. When ALLocate was applied to marrow smears, its leukemia detection results were similar to results from a doctor but were produced much faster. This is the first report to integrate a deep learning system with a low-cost microscope scanner system for leukemia detection with high performance, which can benefit small community practices and clinics in underserved areas, making healthcare more accessible and affordable to all.
Image Classification on Satellite Imagery For Sustainable Rainwater Harvesting Placement in Indigenous Communities of Northern Tanzania
Roshan Taneja and Yuvraj Taneja, Sacred Heart Preparatory, CA, USA
Abstract: In the remote regions of Northern Tanzania, women and children of the Maasai Tribe walk nine hours a day to collect water. Over four years, collaborative efforts with the Maasai communities have led to the installation of water harvesting units, enhancing the local socio-economic conditions by facilitating educational opportunities and economic pursuits for over 4,000 individuals. This project is a novel approach to integrating satellite data and image classification to identify densely populated areas marked by uniquely shaped Maasai homes. It will also use density maps to plan the best placement of rainwater harvesting units to help 30,000 Maasai. The backbone of this project was developing an image classification model trained on 10,000 hand-selected satellite image samples of Bomas (Maasai living units). This model generated a density heat map, enabling strategically placing rainwater harvesting units in the most critical locations to maximize impact. The project underscores the use of satellite technology and machine learning to address humanitarian needs such as water, particularly in harder-to-reach areas with no infrastructure.
Multimodal Representation Learning using Adaptive Graph Construction
Weichen Huang, St. Andrew’s College, Ireland
Abstract: Multimodal contrastive learning trains neural networks by leveraging data from heterogeneous sources such as images and text. Yet, many current multimodal learning architectures cannot generalize to an arbitrary number of modalities and need to be hand-constructed. We propose AutoBIND, a novel contrastive learning framework that can learn representations from an arbitrary number of modalities through graph optimization. We evaluate AutoBIND on Alzhiemer’s disease detection because it has real-world medical applicability and it contains a broad range of data modalities. We show that AutoBIND outperforms previous methods on this task, highlighting the generalizablility of the approach
PumaGuard: AI-enabled targeted puma mitigation
Aditya Viswanathan, Adis Bock, Zoe Bent, Tate Plohr, Suchir Jha, Celia Pesiri, Sebastian Koglin, and Phoebe Reid, Los Alamos High School, NM, USA
Abstract: We have trained a machine learning classification algorithm to detect mountain lions from trail cam images. This algorithm will be part of a targeted mitigation tool to deter mountain lions from attacking livestock at the local stables. Our algorithm that uses the Xception algorithm is 99% accurate in training, 91% accurate on validation and successful in identifying mountain lions at the stables.
Spotlighted Projects
Diagnosing Tuberculosis Through Digital Biomarkers Derived From Recorded Coughs
Sherry Dong, Skyline High School, MI, USA
GeoAgent: Precise Worldwide Multimedia Geolocation with Large Multimodal Models
Tianrui Chen, Shanghai Starriver Bilingual School, China
INAVI: Indoor Navigation Assistance for the Visually Impaired
Krishna Jaganathan, Waubonsie Valley High School, IL, USA
Implementing AI-driven Techniques for Monitoring Bee activities in Hives
Tahmine Dehghanmnashadi, Shahed Afshar High School for Girls, Iran
AquaSent-TMMAE: A Self-Supervised Learning Method for Water Quality Monitoring
Cara Lee, Woodside Priory School, CA, USA; Andrew Kan, Weston High School, MA, USA; and Christopher Kan, Noble and Greenough School, MA, USA
AAVENUE: Detecting LLM Biases on NLU Tasks in AAVE via a Novel Benchmark
Abhay Gupta, John Jay Senior High School, NY, USA; Philip Meng, Phillips Academy, MA, USA; and Ece Yurtseven, Robert College, Turkey
FireBrake: Optimal Firebreak Placements for Active Fires using Deep Reinforcement Learning
Aadi Kenchammana, Saint Francis High School, CA, USA
Vision-Braille: An End-to-End Tool for Chinese Braille Image-to-Text Translation
Alan Wu, The High School Affiliated to Renmin University of China, China
Advancing Diabetic Retinopathy Diagnosis: A Deep Learning Approach using Vision Transformer Models
Rhea Shah, Illinos Mathematics & Science Academy, IL, USA
LocalClimaX: Increasing Regional Accuracy in Transformer-Based Mid-Range Weather Forecasts
Roi Mahns and Ayla Mahns, Antilles High School, Puerto Rico, USA
HypeFL: A Novel Blockchain-Based Architecture for a Fully-Connected Autonomous Vehicle System using Federated Learning and Cooperative Perception
Mihika A. Dusad and Aryaman Khanna, Thomas Jefferson High School for Science and Technology, VA, USA
Robustness Evaluation for Optical Diffraction Tomography
Warren M. Xie, Singapore American School, Singapore
Translating What You See To What You Do: Multimodal Behavioral Analysis for Individuals with ASD
Emily Yu, Pittsford Mendon High School, NY, USA
SignSpeak: Open-Source Time Series Classification for ASL Translation
Aditya Makkar, Divya Makkar, and Aarav Patel, Turner Fenton Secondary School, ON, Canada
SeeSay: An Assistive Device for the Visually Impaired Using Retrieval Augmented Generation
Melody Yu, Sage Hill School, CA, USA
Predicting Neurodevelopmental Disorders in rs-fMRI via Graph-in-Graph Neural Networks
Yuhuan Fan, The Experimental High School Attached to Beijing Normal University, China
Realistic B-mode Ultrasound Image Generation from Color Flow Doppler using Deep Learning Image-to-Image Translation
Sarthak Jain Silver Creek High School, CA, USA
NeurIPS 2024 Registration Changes
Registration for NeurIPS 2024 has exceeded our initial expectations. To ensure that authors of accepted conference and workshop papers are given priority, we are transitioning from our usual first-come-first-serve registration model to a randomized lottery system, effective immediately. While we are currently reserving spots for all conference and workshop paper authors, this may change as the conference approaches and we open up remaining slots to the lottery, so we urge authors to register as soon as possible to guarantee their spot. To register, please use our registration page: https://neurips.cc/Register/. If you are an author on a conference or workshop paper, registration will be open to you. Otherwise, you will be re-directed to our lottery system.
If you have an accepted main conference or workshop paper and are still redirected to the lottery, please attempt the following troubleshooting steps:
- You may have multiple neurips.cc accounts, and you are not logged onto the one that is linked to your paper. Log onto the correct account.
- You have a workshop paper, but the organizers of the workshop have not imported their papers. Please wait for the workshop organizers to do so and contact them with any inquiries.
- Your neurips.cc profile does not contain a first name, last name, and institution. Please update this information.
NeurIPS 2024 October Newsletter
Welcome to the October edition of the NeurIPS monthly Newsletter!
The NeurIPS Newsletter aims to provide an easy way to keep up to date with NeurIPS events and planning progress, respond to requests for feedback and participation, and find information about new initiatives. Notably, this newsletter will focus on NeurIPS 2024, held in Vancouver, from Tuesday, Dec 10 to Sunday, Dec 15, 2024.
You are receiving this newsletter as per your subscription preferences in your NeurIPS profile. As you prepare to attend NeurIPS, we hope that you will find the following information valuable. To unsubscribe from the NeurIPS newsletter, unselect the “Subscribe to Newsletter” checkbox in your profile: https://neurips.cc/Profile/subscribe. To update your email preference, visit: https://neurips.cc/FAQ/EmailPreferences
Newsletter includes:
- Introducing the NeurIPS 2024 Tutorials
- Announcing the NeurIPS 2024 Affinity Events
- NeurIPS Town Hall Scheduled
- Live streaming at Pinnacle Hotel Waterfront
- Poster Information and Printing Service
- Childcare and and Other Amenities
- Dietary Restrictions
- Conference Dates and NeurIPS EXPO
1) Introducing the NeurIPS 2024 Tutorials
The NeurIPS 2024 tutorials will be held on Tuesday, Dec 10. There will be 14 tutorials this year. All of them will be conducted in person to encourage active participation and some of them include panels to allow for a diverse range of discussion. For a list of accepted tutorials and their speakers, refer to our blog post here.
2) Announcing the NeurIPS 2024 Affinity Events
We are excited to announce this year’s affinity events co-located with NeurIPS. At NeurIPS, affinity groups play a crucial role in promoting and supporting the ideas and voices of various communities that are defined by some axis of joint identity and raise awareness of issues that affect their members. In addition, they provide members of these affinity groups with increased opportunities to showcase their work, engage in discussions, and build connections during NeurIPS events, promoting diversity and inclusion at NeurIPS. For more information, please visit the Affinity Events Website.
3) NeurIPS Town Hall Scheduled
The NeurIPS Town Hall will be held on Friday December 13th at 7 PM this year, before the closing reception. The Town Hall provides community members with an opportunity to hear updates and ask questions about the conference and its organisation. The town hall lasts for an hour, with the first 30 minutes dedicated to presentations from various chairs and the last 30 minutes dedicated to an open Q&A from the community.
4) Live streaming at Pinnacle Hotel Waterfront
NeurIPS 2024 is partnering with the Pinnacle Hotel Waterfront to provide live streaming of the Invited Speaker talks. Attendees staying at the Pinnacle Hotel can enjoy the talks from the hotel itself, in the Harbourfront Ballroom. To access this room, attendees will need to show their room key and NeurIPS badge. Complimentary snacks and coffee will be provided.
Talks streamed at the Pinnacle:
Wednesday, December 11 at 8:30am, Sepp Hochreiter
Wednesday, December 11 at 2:30pm, Fei Fei Li
Thursday, December 12 at 8:30am, Zhou Lidong
Thursday, December 12 at 2:30pm, Arnaud Doucet
Friday, December 13 at 8:30am, Danica Kragic
Friday, December 13 at 2:30pm Rosalind Picard
Note: The Tuesday, December 10th talk with Alison Gopnik may be seen at the VCC, West level 0, Hall C or streamed from your mobile device.
5) Poster Presentation and Printing Service
An email with the subject “NeurIPS 2024 Update Poster Presentation Details” has been sent to all authors. If an author has not received the email they should check their spam folder and/or check that the email on their account at NeurIPS is the correct email address with this link (https://neurips.cc/MyStuff).
Read the NeurIPS poster printing information page for additional insight and information about templates, virtual poster and paper thumbnails, poster sizes and printing.
You can use any service you want to print your poster. We offer an optional poster printing service.
6) Childcare and and Other Amenities
NeurIPS is proud to provide free on-site child care. Please register before the Nov 8th at 5 pm PST deadline and familiarise yourself with the cancelation policy to avoid no-show fees. For details and how to register visit: https://neurips.cc/Conferences/2024/Children.
Other amenities will include a nursing room and first aid.
7) Dietary Restrictions
Dietary restrictions should be updated in each registration profile by November 1. After November 1, we are unable to guarantee supporting dietary restrictions. We will do our best to still accommodate you if you have not met the deadline date, but we cannot guarantee.
8) Conference Dates and NeurIPS EXPO
The conference start date has been changed to Tuesday December 10 in order to support delegates arriving on Monday for the Tuesday morning sessions. Registration will now open on Monday from 1 pm to 6 pm. Tutorials remain on Tuesday as originally scheduled. We encourage all attendees to verify dates directly on our website (https://neurips.cc/Conferences/2024) to avoid confusion.
This year’s NeurIPS features an exciting lineup of 56 Expo events across December 10th-11th. This includes 18 interactive demonstrations on Tuesday December 10th, along with 26 talk panels and 12 workshops spread across both days. Grab a coffee or box lunch and engage in an EXPO talk or workshop. Demos will be available on the exhibit sponsor hall floor.
Thanks and looking forward to seeing you at the conference.
Amir Globerson & Lester Mackey
NeurIPS 2024 General Chairs
Announcing the NeurIPS 2024 Affinity Events
By Ioana Bica, Nezihe Merve Gürel
We are excited to announce this year’s affinity events co-located with NeurIPS.
What are affinity groups?
At NeurIPS, affinity groups play a crucial role in promoting and supporting the ideas and voices of various communities that are defined by some axis of joint identity and raise awareness of issues that affect their members. In addition, they provide members of these affinity groups with increased opportunities to showcase their work, engage in discussions, and build connections during NeurIPS events, promoting diversity and inclusion at NeurIPS.
The main goals of affinity events are to increase visibility of the work done by the members of the affinity group, enable them to interact and discuss topics that are unique to each affinity group, encourage affinity group members to showcase their work and step into the NeurIPS community. In contrast to regular workshops, affinity group workshops adopt a more open and flexible approach around topic area, focusing on forming research communities within the affinity groups and bringing attention to the unique challenges faced by their members.
Additionally, affinity group socials serve as safe and welcoming spaces, allowing members to interact, socialize, and network in an inclusive environment. By fostering such social gatherings, NeurIPS supports the creation of a supportive community that values diversity and ensures that all voices are heard and valued.
What kind of events do affinity groups offer at conferences?
Affinity groups organize events with the main aim to encourage people to showcase their work and step into the NeurIPS community. The affinity events at NeurIPS this year will take place throughout the conference week. See below the details for when each affinity event will take place. NeurIPS will offer streaming support for all the in-person components of the affinity groups.
What can NeurIPS attendees do to support affinity groups?
Participate! Actively attending and participating in panels and sessions for discussions about issues that are relevant to the affinity groups goes a long way in helping promote their cause. We request all members of our community to participate actively!
Affinity groups at NeurIPS 2024
We are delighted to announce the following affinity groups at NeurIPS 2024. Find out more below about their mission and the event they are organizing!
Indigenous in AI/ML
Indigenous In AI’s vision is to build an international community of Native, Aboriginal, and First Nations who will collectively transform their home communities with advanced technology. By elevating the voices of Indigenous ML researchers we will inspire future impactful work and break stereotypes. Additionally, this group will strive to educate the broader NeurIPS on contemporary indigenous issues relevant to information technology and practices. For more information, please visit the Indigenous in AI website.
Muslims in ML
The Muslims in ML workshop aims to explore the intersection of machine learning, fairness, and the global Muslim community. It recognizes the potential of AI and ML to bring positive changes but also acknowledges existing barriers and biases that may perpetuate unfairness against Muslims. The workshop, now in its 3rd edition, aims to bring together diverse experts and perspectives to examine challenges and opportunities in integrating AI/ML in the lives of Muslims and those in Muslim-majority countries. It will showcase research by Muslim scholars in ML and highlight work addressing challenges faced by the Muslim community. The workshop provides a safe space for open discussions and social activities. It adopts an inclusive approach that considers cultural association and proximity to the Muslim identity, emphasising the importance of understanding the complexity and diversity within the Muslim community. The workshop seeks to promote awareness, collaboration, and mitigation strategies to ensure fair and equitable implementation of AI/ML technologies for Muslims worldwide. For more information, please visit the Muslims in ML website.
New in ML workshop
The NewInML workshop is dedicated to fostering an inclusive and supportive environment for emerging researchers in the ML community, with a strong belief that great innovations can arise from students of diverse backgrounds. We have extended our audience to include students at all levels, recognizing the diverse needs of those early in their journey as well as those transitioning within their careers. By offering a platform that spans a broad spectrum of topics—from hands-on sessions to frontier discussions—the workshop provides essential guidance to help participants contribute effectively to the field. Our goal is to build a more inclusive ML community by mentoring attendees, refining their research skills, and empowering them to make meaningful contributions, whether in academia or industry. NewInML workshop will take place Tuesday December 10th. More information can be found on the Workshop’s website.
Neurodivergent Community
The Neurodiversity Workshop will gather the Neurodiverse community to engage on leading research in the space and launch a competition to inspire additional research. The Workshop will be led by expertise from Michigan State University, MIT, Princeton, and more. The Workshop will occur on Thursday December 12 at 12pm Pacific Time. More information can be found on the Workshop’s website.
Global South in AI
Global South in AI (GSAI) was born in 2022 to solve the lack of inclusion and representation of the Global South in artificial intelligence ecosystems, especially the myriad rich vastness of culture and languages lived, spoken by millions of humans, and not just those with access and privilege. GSAI stands as counterbalance to a western lens focused pass-through of all language translation in LLMs and the impact of such homogenization on the global south. We do this through multiple projects that help local researchers who are already working on including their local culture and language in AI to build low resource datasets and empower their community in AI literacy. We also host annual multidisciplinary academic meetups co-located with NeurIPS, with the highest ethical standards for a diverse and inclusive community in order to promote the exchange of research achievements in Language artificial intelligence and machine learning. Please check our website and connect with us on LinkedIn. Our workshop date this year is Dec 10th, 10AM to 3PM at NeurIPS in Vancouver Canada. Details will be announced soon.
Women in ML
The goals and activities of WiML are to
- Highlight the work of researchers in machine learning who are women or non-binary,
- Give them a chance to meet, encourage technical discussion, and future collaboration,
- Give junior researchers an opportunity to present their work to their peers as well as senior members of the community.
The workshop plans to feature speakers who are women or nonbinary to give talks on their research, organize mentorship sessions to discuss relevant topics, and encourage networking. It will encourage and foster research conversations and help participants develop collaboration opportunities. There will also be poster sessions for participants to present a broader array of work and exchange feedback. The workshop will take place on Tuesday, December 10. For more information, please visit the Women in ML website.
Queer in AI
The Queer in AI workshop and social events at NeurIPS 2024 aim to create a vibrant and inclusive space that brings together queer students, researchers, and practitioners from across the globe to critically examine the impact of AI on the LGBTQIA* community, while fostering a sense of belonging among participants. The workshop aspires to build a strong network of queer individuals, enable discussions at the intersection of AI and queer identities, and tackle issues of discrimination within the tech industry and society at large.
The Queer in AI workshop is dedicated to advancing equitable AI practices and contributing to a future where technology serves the needs of all communities. The workshop is committed to advocating for a more ethically grounded approach to AI development, ensuring that diverse voices are heard and valued in conversations about the future of technology. For further details, please visit the Queer in AI website.
LatinX in AI
LatinX in AI (LXAI) bridges communities, academics, industry, and politicians working to further AI innovation and resources for LatinX individuals globally. We drive and support research, development, infrastructure, and mentoring programs to boost innovation and capabilities of LatinX professionals working in Artificial Intelligence, Machine Learning, and Data Science.
The 7th Annual Latinx in AI Research workshop will be held on December 10th, 2024 and will embrace a hybrid format, welcoming attendees both onsite and virtually. The workshop is a one-day event with invited speakers, oral presentations, and posters. The event brings together faculty, graduate students, research scientists, and engineers for an opportunity to connect and exchange ideas. There will be a panel discussion and a mentoring session to discuss current research trends and career choices in Artificial Intelligence and Machine Learning. While all presenters will identify primarily as LatinX, all are invited to attend. For further details, please visit the Latinx in AI website.
Black in AI
Black in AI aims to shift the power dynamic in the field of artificial intelligence by broadening the range of voices contributing to the development, deployment, and regulation of AI technologies – to ensure that our community members are full partners in affirming their technological and economic futures. NeurIPS, being one of the largest AI research conferences, offers a valuable opportunity for researchers in the community to stay updated on the latest research and expand their network. Since its inception in 2017, many participants of the Black in AI Workshop have walked away from their experience at NeurIPS with internship offers, graduate program advisors, mentorships, and renewed energy to continue working in the field. The workshop remains committed to bridging the gap between researchers of African descent and the AI community at large. For more information, please visit the Black in AI website.
Introducing the NeurIPS 2024 Tutorials
by Andrew M. Dai, Irene Chen, Gal Chechik
We are excited to present the list of tutorials selected to present at the NeurIPS 2024 conference! We look forward to a programme that we hope will engage the attendees with topics ranging from experimental design for AI researchers and meta-generation algorithms for LLMs through to cross-disciplinary insights into alignment. In this post, we will describe this year’s programme and our selection process.
Program
There will be 14 tutorials this year. All of them will be conducted in person to encourage active participation and some of them include panels to allow for a diverse range of discussion. The tutorials selected this year with their speakers are:
Flow Matching for Generative Modeling
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu
Cross-disciplinary insights into alignment in humans and machines
Gillian Hatfield, Joel Z. Leibo, Dylan Hadfield-Menell
Experimental Design and Analysis for AI Researchers
Katherine Hermann, Jennifer Hu, Mike Mozer
Generating Programmatic Solutions: Algorithms and Applications of Programmatic Reinforcement Learning and Code Generation
Shao-Hua Sun, Levi Lelis, Xinyun Chen
Evaluating Large Language Models – Principles, Approaches, and Applications
Irina Sigler, Yuan (Emily) Xue, Bo Li
Beyond Decoding: Meta-Generation Algorithms for Large Language Models
Sean Welleck, Hailey Schoelkopf, Matthew Finlayson
Opening the Language Model Pipeline: A Tutorial on Data Preparation, Model Training, and Adaptation
Akshita Bhagia, Nathan Lambert, Kyle Lo
Dynamic Sparsity in Machine Learning: Routing Information through Neural Pathways
Edoardo M. Ponti, André F. T. Martins
Advancing Data Selection for Foundation Models: From Heuristics to Principled Methods
Jiachen T. Wang, Ruoxi Jia, Ludwig Schmidt
Watermarking for Large Language Model
Xuandong Zhao, Yu-Xiang Wang, Lei Li
Sandbox for the Blackbox: How LLMs Learn Structured Data?
Ashok Vardhan Makkuva, Bingbin Liu, Jason D. Lee
Out-of-Distribution Generalization: Shortcuts, Spuriousness, and Stability
Yoav Wald, Aahlad Puli, Maggie Makar
Causality for Large Language Models
Zhijing Jin, Sergio Garrido
Meaningful Evaluations of ML Privacy Techniques: What Are We Waiting For
Mimee Xu, Fazl Barez, Dmitrii Usynin
Selection process
We received 57 unique tutorial proposals this year with roughly half of them related to large language models. Each submission was reviewed by at least one tutorial chair with the accepted tutorials receiving at least two reviews. Review assignments were chosen based on the area of expertise and to avoid conflicts of interest. Each chair gave a score from 1-5 on three categories, the speaker/panelist quality, the topic (interestingness, importance, timeliness) and appropriateness (suitability for the NeurIPS audience).
Common reasons for lower scores included:
- Topics that were too niche for the general NeurIPS audience.
- Significant overlap with stronger proposals.
- Insufficient diversity among the speakers.
- Too much expectation of familiarity with specific software or hardware.
- Too much overlap with past tutorials.
Choosing the final tutorials from the high scoring ones was a challenging task and we appreciate all the work that went into these proposals. We will be doing run-throughs with the selected tutorials to offer advice and feedback.
Keep your eyes on a post-conference retrospective blog post with reflections on tutorials. Please feel free to reach out to us at tutorial-chairs@neurips.cc if you have any suggestions.
By Yixuan Even Xu, Fei Fang, Jakub Tomczak, Cheng Zhang, Zhenyu Sherry Xue, Ulrich Paquet, Danielle Belgrave
Overview
Paper assignment is crucial in conference peer review as we need to ensure that papers receive high-quality reviews and reviewers are assigned papers that they are willing and able to review. Moreover, it is essential that a paper matching process mitigates potential malicious behavior. The default paper assignment approach used in previous years of NeurIPS is to find a deterministic maximum-quality assignment using linear programming. This year, for NeurIPS 2024, as a collaborative effort between the organizing committee and researchers from Carnegie Mellon University, we experimented with a new assignment algorithm [1] that introduces randomness to improve robustness against potential malicious behavior, as well as enhance reviewer diversity and anonymity, while maintaining most of the assignment quality.
TLDR
How did the algorithm do compared to the default assignment algorithm? We compare the randomized assignment calculated by the new algorithm to that calculated from the default algorithm. We measure various randomness metrics [1], including maximum assignment probability among all paper-reviewer pairs, the average of maximum assignment probability to any reviewer per paper, L2 norm, entropy, and support size, i.e., the number of paper-reviewer pairs that could be assigned with non-zero probability. As expected, the randomized algorithm was able to introduce a good amount of randomness while ensuring the overall assignment quality is
Also, one key takeaway from our analysis is that it is important for all the reviewers to complete their OpenReview profile and bid actively to get high-quality assignments. In fact, among all reviewers who bid “High” or “Very High” for at least one paper,
In the rest of this post, we introduce the details of the algorithm, explain how we implemented it, and analyze the deployed assignment for NeurIPS 2024.
The Algorithm
The assignment algorithm we used is Perturbed Maximization (PM) [1], a work published at NeurIPS 2023. To introduce the algorithm, we first briefly review the problem setting of paper assignment in peer review as well as the default algorithm used in previous years.
Problem Setting and Default Algorithm
In a standard paper assignment setting, a set
The optimization above can be solved efficiently by linear programming and is widely used in practice. In fact, the default automatic assignment algorithm used in OpenReview is also based on this linear programming formulation and has been used for NeurIPS in past years.
Perturbed Maximization
While the deterministic maximum-quality assignment is the most common, there are strong reasons [1] to introduce randomness into paper assignment, i.e., to determine a probability distribution over feasible deterministic assignments and sample one assignment from the distribution. For example, one important reason is that randomization can help mitigate potential malicious behavior in the paper assignment process. Several computer science conferences have uncovered “collusion rings” of reviewers and authors [15-16], in which reviewers aim to get assigned to the authors’ papers in order to give them good reviews without considering their merits. Randomization can help break such collusion rings by making it harder for the colluding reviewers to get assigned to the papers they want. The randomness will also naturally increase reviewer diversity and enhance reviewer anonymity.
Perturbed Maximization (PM) [1] is a simple and effective algorithm that introduces randomness into paper assignment. Mathematically, PM solves a perturbed version of the optimization problem above, parameterized by a number
In this perturbed optimization, the variables
After solving the optimization problem above, we obtain a probabilistic assignment matrix
Implementation
Since this is the first time we use a randomized algorithm for paper assignment at NeurIPS, the organizing committee decided to set the parameters so that the produced assignment is close in quality to the maximum-quality assignment, while introducing a moderate amount of randomness. Moreover, we introduced additional constraints to ensure that the randomization does not result in many low-quality assignments.
Similarity Computation of NeurIPS 2024
The similarity matrix
Additional Constraints for Restricting Low-Quality Assignments
One of the main concerns of paper assignment in large conferences like NeurIPS is the occurrence of low-quality assignments because the matching quality of any individual paper-reviewer pair significantly affects the relevance of both papers and reviewers. To mitigate this issue, we explicitly restrict the number of low-quality assignments. Specifically, we first solve another optimization problem without the perturbation function [17]:
Let the optimal solution of this problem be
The thresholds
Running the Algorithm
We integrated the Python implementation of PM into the OpenReview system, using Gurobi [19] as the solver for the concave optimization. However, since the number of papers and reviewers in NeurIPS 2024 is too large, we could not directly use OpenReview’s computing resources to solve the assignment in early 2024. Instead, we ran the algorithm on a local server with anonymized data. The assignment was then uploaded to OpenReview for further processing, such as manual adjustments by the program committee. We ran four different parameter settings of PM and sampled three assignments from each setting. Each parameter setting took around 4 hours to run on a server with 112 cores, using peak memory of around 350GB. The final assignment was chosen by the program committee based on the computed statistics of the assignments. The final deployed assignment came from the parameter setting where
Analysis of The Deployed Assignment
How did the assignment turn out? We analyzed various statistics of the assignment, including the aggregate scores, affinity scores, reviewer bids, reviewer load, and reviewer confidence in the review process. We also compared the statistics across different subject areas. Here are the results.
Aggregate Scores
The deployed assignment achieved an average aggregate score of
Affinity Scores
Since the aggregate score is the sum of the affinity score based on text similarity and the converted reviewer bids, we also checked the distribution of these two key scores. The deployed assignment achieved high affinity scores, with an average of
Reviewer Bids
For reviewer bids, we see that most of the assigned pairs have “Very High” bids from the reviewers, with the majority of the rest having “High” bids. Moreover, not a single pair has a negative bid. This indicates that reviewers are generally interested in the papers they are assigned to. Note that although we default missing bids to “Neutral”, the number of matched pairs with “Missing” bids is larger than that of pairs with “Neutral” bids. This is because if a reviewer submitted their bids, they are most likely assigned to the papers they bid positively on. The matched pairs with “Missing” bids are usually those where reviewers did not submit their bids, and the assignment for them was purely based on the affinity scores.
Reviewer Load
If we distribute the reviewer load evenly, reviewers should be assigned to an average of
Nevertheless, some reviewers in the pool are not assigned to any papers or are assigned to only one paper. After analyzing the data more carefully, we found that most of these reviewers either had no known affinity scores with the papers (mostly because they did not have any past work on OpenReview) or did not submit their bids. Moreover, there are even
We suggest that reviewers submit their bids and provide more information about their past work to help the algorithm find better matches for them.
While the reviewer load distribution for each subject area generally follows the overall distribution, we note that some subject areas, like Bandits, have a notably higher number of papers assigned to each reviewer. In fact, most reviewers in the Bandits area were assigned to
Reviewer Confidence
In the review process, reviewers were asked to provide their confidence in their reviews on a scale from
On a side note, we found that reviewer confidence is generally lower for theoretical areas like Algorithmic Game Theory, Bandits, Causal Inference, and Learning Theory, while it is higher for other areas. It is hard to explain this phenomenon exactly, but we think this might be because the difficulty of reviewing papers in theoretical areas is generally higher, leading reviewers to be more cautious in their reviews.
Comparison with the Default Algorithm
Besides analyzing the deployed assignment, it is also natural to ask how the new algorithm PM compares to the default algorithm used in OpenReview. To answer this question, we ran the default algorithm on the same data and compared the resulting assignment with the deployed assignment. Below, we show the comparison with the default algorithm in aggregate scores, reviewer bids, and reviewer load.
Aggregate Scores
In terms of aggregate scores, the default algorithm achieved an average of
Reviewer Bids
How do the sampled assignments resulting from the new algorithm differ from the default one? Here we show the distribution of reviewer bids in the default assignment, the overlap between the optimal deterministic assignment and the deployed assignment, and the overlap between the optimal deterministic assignment and three sampled assignments from PM. As seen in the following figure, a non-negligible number of matched pairs have changed from the default assignment to the deployed assignment, and over half of the matched pairs would be different in three samples from PM. This indicates that PM introduces a good amount of randomness into the assignment, increasing robustness against malicious behavior while incurring only a small loss in matching quality.
Reviewer Load
Another side benefit of PM is that it can help distribute the reviewer load more evenly. In the following figure, we show the distribution of reviewer load in the optimal deterministic assignment and the deployed assignment. We can see that both the number of reviewers assigned to
Conclusion
In this post, we introduced the paper assignment algorithm used for NeurIPS 2024 and explained how we implemented it. We analyzed the results of the assignment and compared it with the default algorithm used in OpenReview. We found that the assignment produced by the new algorithm achieved high-quality matches, with a good amount of randomness introduced into the assignment, increasing robustness against malicious behavior as well as enhancing reviewer diversity and anonymity. In future conferences, we suggest that reviewers submit their bids and provide more information about their past work to help the algorithm find better matches for them.
References
[1] Xu, Yixuan Even, Steven Jecmen, Zimeng Song, and Fei Fang. “A One-Size-Fits-All Approach to Improving Randomness in Paper Assignment.” Advances in Neural Information Processing Systems 36 (2024).
[2] Charlin, Laurent, and Richard Zemel. “The Toronto paper matching system: an automated paper-reviewer assignment system.” (2013).
[3] Stelmakh, Ivan, Nihar Shah, and Aarti Singh. “PeerReview4All: Fair and accurate reviewer assignment in peer review.” Journal of Machine Learning Research 22.163 (2021): 1-66.
[4] Jecmen, Steven, Hanrui Zhang, Ryan Liu, Fei Fang, Vincent Conitzer, Nihar B. Shah. “Near-optimal reviewer splitting in two-phase paper reviewing and conference experiment design.” Proceedings of the AAAI Conference on Human Computation and Crowdsourcing. Vol. 10. 2022.
[5] Tang, Wenbin, Jie Tang, and Chenhao Tan. “Expertise matching via constraint-based optimization.” 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology. Vol. 1. IEEE, 2010.
[6] Flach, Peter A., Sebastian Spiegler, Bruno Golenia, Simon Price, John Guiver, Ralf Herbrich, Thore Graepel and Mohammed J. Zaki. “Novel tools to streamline the conference review process: Experiences from SIGKDD’09.” ACM SIGKDD Explorations Newsletter 11.2 (2010): 63-67.
[7] Taylor, Camillo J. “On the optimal assignment of conference papers to reviewers.” University of Pennsylvania Department of Computer and Information Science Technical Report 1.1 (2008): 3-1.
[8] Charlin, Laurent, Richard S. Zemel, and Craig Boutilier. “A Framework for Optimizing Paper Matching.” UAI. Vol. 11. 2011.
[9] Shah, Nihar B. “Challenges, experiments, and computational solutions in peer review.” Communications of the ACM 65.6 (2022): 76-87.
[10] Mimno, David, and Andrew McCallum. “Expertise modeling for matching papers with reviewers.” Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. 2007.
[11] Liu, Xiang, Torsten Suel, and Nasir Memon. “A robust model for paper reviewer assignment.” Proceedings of the 8th ACM Conference on Recommender systems. 2014.
[12] Rodriguez, Marko A., and Johan Bollen. “An algorithm to determine peer-reviewers.” Proceedings of the 17th ACM conference on Information and knowledge management. 2008.
[13] Tran, Hong Diep, Guillaume Cabanac, and Gilles Hubert. “Expert suggestion for conference program committees.” 2017 11th International Conference on Research Challenges in Information Science (RCIS). IEEE, 2017.
[14] Goldsmith, Judy, and Robert H. Sloan. “The AI conference paper assignment problem.” Proc. AAAI Workshop on Preference Handling for Artificial Intelligence, Vancouver. 2007.
[15] Vijaykumar, T. N. “Potential organized fraud in ACM.” IEEE computer architecture conferences. Online https://medium.com/@tnvijayk/potential-organized-fraud-in-acm-ieee-computer-architecture-conferences-ccd61169370d Last accessed April. Vol. 4. 2020.
[16] Littman, Michael L. “Collusion rings threaten the integrity of computer science research.” Communications of the ACM 64.6 (2021): 43-44.
[17] Jecmen, Steven, Hanrui Zhang, Ryan Liu, Nihar B. Shah, Vincent Conitzer and Fei Fang. “Mitigating manipulation in peer review via randomized reviewer assignments.” Advances in Neural Information Processing Systems 33 (2020): 12533-12545.
[18] Budish, Eric, Yeon-Koo Che, Fuhito Kojima and Paul Milgrom. “Implementing random assignments: A generalization of the Birkhoff-von Neumann theorem.” Cowles Summer Conference. Vol. 2. No. 2.1. 2009.
[19] Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2023.