AI-Generated Papers in the NeurIPS 2026 Position Paper Track
This year, the NeurIPS 2026 Position Paper Track made the decision to require that all papers be substantially human-written, with AI used for only copy-editing or similar peripheral changes to the main text. While we recognize that thoughtful use of AI can result in productivity gains in research, the use of AI to write papers creates an acute risk for the peer review system. As Position Paper Track chairs, we took a conservative approach in policy this year as we believe in argumentative work like position papers, excessive use of AI in writing submitted papers has little benefit for the research community as a whole. AI-generated text is often slick, but can depart significantly from the authors’ original intention. In this case, submitting AI-generated text for peer review externalises the cost of verifying that work, imposing it on reviewers. Where AI-generated text is not itself incoherent or otherwise misguided, this raises questions about the appropriate attribution of credit.
To assess if authors were largely abiding by this policy, we partnered with Pangram, a leading AI detection modeling company. We worked closely with Pangram to ensure, as per their enterprise-level data agreement, that zero data would be retained through the usage of their model. After several independent analyses to verify the correctness of this model and rule out scenarios in which significant false positives would be created, we are now making the difficult decision to uphold our policy, under which:
- 178 submissions (18.4% of all submissions) will be desk rejected
- 123 submissions (12.7%) will be requested to provide evidence of substantial human engagement or risk a desk reject.
In this blog post, we will lay out our analyses informing this decision, and provide our perspective as organizers.
Why this policy?
We reproduce here the 2026 PPT AI policy:
Use of AI: While we recognise the productivity gains that can be realised through judicious use of AI in research, due to the risk to the integrity of individual projects and of the review system as a whole, the position paper track is establishing the following explicit guardrails on AI use in preparing and reviewing submissions.
- While AI tools may be used in the research that leads to the final paper, the final paper must itself be substantially written by human authors, meaning that AI is used only for copy-editing or similar peripheral changes to the main text.
- At submission time, authors will be required to state how AI tools were used in the preparation of the paper, if at all, and to attest that they have not used AI in ways contrary to the above rule.
- Because papers submitted to the position paper track are confidential, reviewers will be required to commit to not using AI tools to write their reviews.
- Reviewers and authors found to have contravened their commitments not to use AI may be subject to desk-rejection of any work submitted to the position paper track.
- Note that the Position Paper Track’s LLM policy differs from the Main Program’s LLM policy. Authors are responsible for understanding policy pertaining to the specific track they are submitting to, and abiding by it.
The use of AI to write papers creates an acute risk to the peer review system. Proactive steps are necessary to build the norms and institutions that will preserve its integrity. This policy is an attempt to begin that process.
It is of course possible that a paper’s authors could use AI responsibly, (1) personally verifying every line of AI output, and (2) ensuring that the AI does nothing more than rephrase ideas for which humans are solely responsible. However, by submitting work that is immediately recognisable and verifiable as being substantially AI-generated, authors make it impossible for readers to know that (1) and (2) obtain, leaving reviewers with little choice but to rely upon author declarations. Unfortunately, given the volume of submissions that appear non-compliant, relying on author declarations is insufficient.
We do not expect that our policy and our approach will be the last word on handling AI-generated research. Every research field will have to confront the same problem, and a range of solutions may be reasonable. We have sought to use the evidence available to us to identify submissions that appear to be non-compliant with our policy. But we are also introducing a new approach to auditing AI use by establishing appropriate provenance. Authors whose submissions show significant AI involvement must provide an audit trail that clearly demonstrates that they complied with the policy. We expect that in future years this kind of audit trail will become a default.
AI detection with Pangram suggests substantial AI use among this year’s submissions
We identified if a submission is significantly AI-written using Pangram, an industry-leading AI detector. Using Pangram (v3.3.2), we found that 28.2% (273 / 969) of submissions substantially used AI for writing. This finding prompted further investigation, which we present in the next sections. We start by providing clarity on what Pangram does.
Given a full text document, Pangram first uses a windowing algorithm to break up the text into text windows, where by default, each window is around 250 to 350 words. Next, Pangram assigns each text window a probability that it contains AI-generated text. If the model’s assigned probability exceeds 0.75, then that window is flagged as AI-generated. From these predictions, each paper receives a Pangram AI score, which is the percentage of windows that are classified as AI-generated. A Pangram AI score of 100% means that all of the words in the paper fall into a text window that Pangram believes contains AI-generated text. A Pangram AI score of 100% should not be interpreted as “100% of the text is AI-generated”, rather that there is substantive use of AI in many parts of the text.
Our preliminary investigation found that 28.2% (273 / 969) of submissions to the NeurIPS 2026 Position Papers Track (PPT) received a Pangram AI score of 100%. We found this number surprisingly high, given internal and external audits of Pangram reported a false positive rate of less than 0.1%, and in previous applications to ICLR 2026 accepted papers, the model only detected that 1% of papers were AI-generated. We contrasted Pangram’s results on the NeurIPS PPT against papers from comparable venues (Table 1). We tested Pangram against papers accepted to ACM FAccT in 2022 and 2025, which are similar in style and content to many NeurIPS position papers. FAccT 2022 papers preceded ChatGPT’s release and served as a negative control. To determine if our findings extend to other NeurIPS tracks, we compare against a sample of 2025 and 2026 submissions to the NeurIPS Evaluations and Datasets (E&D), formerly Datasets & Benchmarks (D&B).
Table 1
Default Pangram AI-detection across conferences.
| Conference | # Papers | Pangram AI Score | ||
| ≥ 50% | ≥ 90% | = 100% | ||
| NeurIPS PPT 2025 | 536 | 28.5% | 11.9% | 8.2% |
| NeurIPS PPT 2026 | 971 | 70.5% | 42.7% | 28.2% |
| NeurIPS D&B 2025 | 996 | 5.6% | 0.8% | 0.4% |
| NeurIPS E&D 2026 | 996 | 43.7% | 9.3% | 2.1% |
| FAccT 2022 | 159 | 0.0% | 0.0% | 0.0% |
| FAccT 2025 | 204 | 1.0% | 1.0% | 0.0% |
We made two observations. First, there are far fewer papers with a Pangram AI score of 90-100% in NeurIPS E&D and FAccT compared to the NeurIPS Position Paper Track. Second, there is a sharp increase in AI use for paper writing in both NeurIPS tracks evaluated; in the Evaluations and Datasets track, papers with a Pangram AI score ≥90% have increased more than tenfold from 2025 to 2026. Taken together, this suggests the high rate of AI use in the NeurIPS Position Paper Track is caused both by factors specific to the track itself, and by a broader significant increase in AI use across the board.
Using smaller text windows leads to more localized AI use at the cost of recall
One challenge to our preliminary findings that “28.2% of submissions have 100% Pangram AI scores” is that Pangram classifies on large text windows (250-350 words, by default), and it is possible that Pangram flags a text as AI-generated, even though only a small portion of the text was written by AI while remaining compliant with our policy. We re-run Pangram using two custom text windowing strategies with strictly fewer words: medium-sized (approx. 100 words) and small-sized (approx. 50 words).
Using smaller window sizes reduces the chances of over-claiming AI use, but it may also worsen the ability of Pangram to truly identify AI-generated text. We assess how window size affects recall on 10 ChatGPT-generated “position papers” (Table 2).
Table 2
Comparison of smaller text windowing strategies and thresholds on Pangram AI score.
| Papers | Windowing | Avg. Pangram AI score | Recall at ≥ Pangram AI score | |||
| ≥ 0.5 | ≥ 0.7 | ≥ 0.9 | = 1.0 | |||
| ai_positions25(N=10) | small | 61.8% | 70% | 30% | 0% | 0% |
| medium | 91% | 100% | 100% | 70% | 0% | |
| default | 100% | 100% | 100% | 100% | 100% | |
These results suggest that 100-word windows result in a lesser drop in recall compared to 50-word windows, so we decided to move forward with medium-sized windows, trading off recall for finer-grained claims on AI use. Using medium-sized windows, the percentage of papers with Pangram AI scores of 90-100% goes down from 42.7% to 12.7% (Table 3).
Table 3
Varying window size on Pangram AI scores in NeurIPS PPT 2026.
| Window size | Pangram AI Score | ||
| ≥ 50% | ≥ 90% | = 100% | |
| medium | 62.3% | 12.7% | 2.16% |
| default | 70.5% | 42.7% | 28.2% |
To ground our findings, we tested Pangram on several writing scenarios with varying AI involvement. We selected 10 papers from FAccT 2022 that resembled position paper track submissions. For each, we extracted a random 100 word text window. Using OpenAI’s GPT 5.5 via OpenRouter, we tested 12 AI use cases. In Table 4, we categorize each use case by their permissibility against our stated policy. We performed two additional experiments. We tested Pangram’s sensitivity to obvious LLM instruction-following text (e.g., “Sure, here is your paragraph”), which we term “AI residue”. Lastly, we tested how sensitive Pangram is to increasing percentages of AI-generated text; we do this by truncating the original text at different amounts from 5% to 95% and asking the LLM to complete the remaining text.
Table 4
AI use cases and permissibility.
| Breaks policy? | Use Case | What it tests |
| Clearly permissible | Proofreading | Request that an LLM edits only spelling, punctuation, grammar, and citation-format cleanup. |
| Light copyediting | Request that an LLM edits only local clarity, concision, awkward phrasing, and sentence-level polish, with no substantive change. | |
| Borderline permissible | Heavy copyediting / line editing | Request that an LLM edits large wording changes and sentence restructuring, while preserving the same claims and reasoning. |
| Structural rewriting | Request that an LLM reorganizes paragraph or argument presentation while preserving the human’s ideas. | |
| Hybrid revision | Human and AI both materially shape the prose, including back-and-forth assistant use or human paraphrasing after AI edits. Tested with Codex, and 5 editing turns (original, AI edits, human edits, AI edits, human edits). | |
| Translation / backtranslation | Request that an LLM translates between languages, so that meaning is preserved, but surface wording may be extensively replaced. | |
| Clearly impermissible | Generation from a single-sentence human plan | A human writes a one-sentence plan/thesis, then AI generates the full passage from it. |
| Substantive AI rewriting | Request that an LLM changes claims, reasoning, framing, or argumentative structure. | |
| Original AI-authored passage | Request that an LLM writes a new position-paper-like passage from examples, topic, or instructions. | |
| Human edits AI work | Human makes minor edits to an original AI-authored passage. | |
| Diagnostic tests | AI residue | Insert obvious chatbot artifacts or AI-styled residue into otherwise human text (e.g. “sure, here is your paragraph:) |
| Partial AI completion | AI receives part of the original human text and completes the rest. Conditions: AI completes 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95% |
For all of the permissible uses, Pangram did not classify any as AI-generated, despite a substantial change in the text (Figure 1A). Meanwhile, clearly impermissible use cases were flagged by Pangram as AI-generated. In our experiment on partial AI completions, Pangram never classified AI completions of 20% or less as AI-generated (Figure 1B). While these experiments were conducted with only 10 text samples, the findings suggest that papers with very high Pangram AI scores were not compliant with our AI use policy.
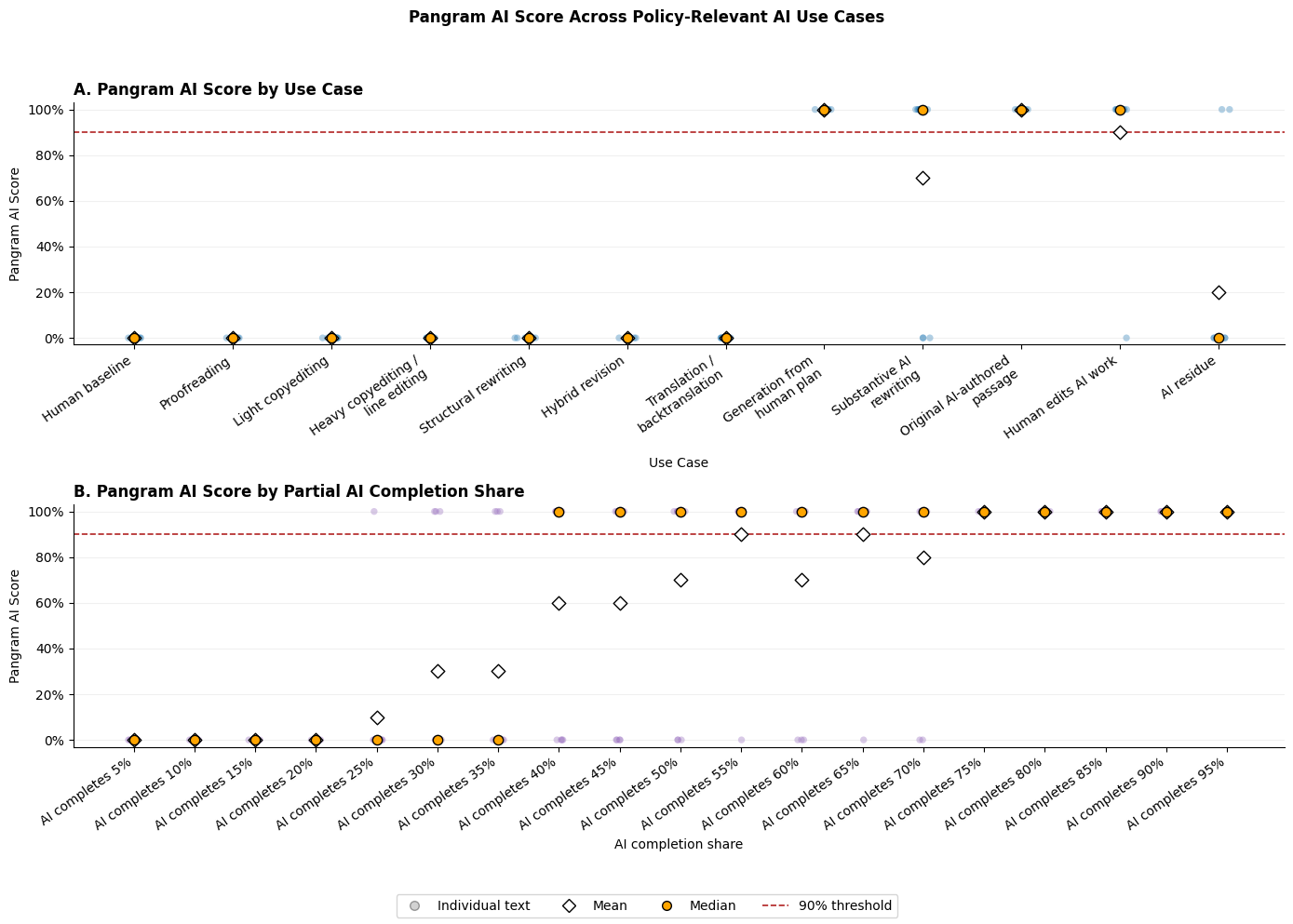
Figure 1
Experiments on AI use and partial AI completion.
Actions to uphold our AI use policy
Our policy stated that AI may be used only for “copy-editing or similar peripheral changes to the main text”. In recognition of the fact that norms in this area are emerging, and these terms are inherently ambiguous, we have adopted conservative decision thresholds designed to minimize false positives (see Table 5 below). We have also incorporated additional supporting evidence, such as authors’ AI use declarations, evidence of policy non-complicance in other submissions, and authors whose submission patterns – including a high number of solo-authored papers – warranted additional scrutiny.
For submissions found to be very likely in breach of our policy, we have chosen two courses of action, based on the strength of the evidence that they are in breach.
- Where we found sufficient evidence of non-compliance with our AI policy, we have issued a standard desk-rejection that is not subject to appeal under standard circumstances.
- Where we have strong but not decisive evidence of non-compliance, we are asking authors to provide evidence supporting that their AI use complied with policy, with details below. Submissions lacking such proof by June 15th, 2026 will also be desk-rejected.
Table 5
Decision Thresholds.
| Outcome | Pangram AI Score | Additional Considerations | # |
| Desk Reject without Appeal | ≥0.9 | None | 77 |
| ≥0.8 | Author has submitted multiple solo-authored papers, with at least one above this threshold OR At least one author has at least one other desk reject | 79 | |
| ≥0.5 | Author declared that they did not use AI, or did not declare AI use | 22 | |
| Total (% of total submissions) | 178 (18.4%) | ||
| Desk Reject with Appeal | ≥0.8<0.9 | None | 123 |
| Total (% of total submissions) | 123 (12.7%) | ||
Appeals Process
It is important to be clear where the burden of proof should lie when it comes to detecting improper use of AI in submissions to a peer-reviewed conference.
Authors who use AI extensively but, in their belief, responsibly, are often indistinguishable from those who have used AI in ways that are not consistent with policy. We have used every available measure to distinguish between these two groups, but we acknowledge there will inevitably be borderline cases.
We believe that it is inappropriate for the research community as a whole to bear the cost of making more fine-grained distinctions among these cases. Authors who limit AI use in their final drafts help reduce burden on the review community. Authors who make more extensive use of AI should maintain clear documentation of their process, which can be shared if requested.
Authors given the opportunity to appeal will be able to provide evidence of responsible AI use in the following form. Well-motivated equivalents may be considered.
- Authors must supply the Track Chairs with a link to an online version of their paper that has a version history including the work before and after the use of AI
- They must identify (1) a “pre-AI” checkpoint indicating that they developed the substantive content of the paper independent of AI, (2) a “post-AI” checkpoint immediately after their most substantive AI-written edits, and (3) the final paper as submitted.
- They must present analysis showing that the AI edits in (2) did not introduce new substantive content that was not present in (1), and of human edits after (2) which demonstrate that (3) was appropriately verified by human authors.
This dossier will be reviewed by the PPT team. Authors who do not wish to appeal may withdraw their paper. We recognize this is a difficult and consequential situation for affected authors, and we encourage anyone with questions to reach out.
Reflections and perspective
The research community faces two overlapping challenges. The first is the impact of irresponsible AI use on our peer review institutions. The second is building consensus on AI use policy, acknowledging there may not be a solution that works across every publication venue, as the community is in substantial disagreement about how to deal with the first.
In formulating our policy on AI use, we explicitly recognised that the careful use of AI can benefit research. We focused narrowly on prohibiting excessive AI use in writing the submitted paper, for the reasons detailed above. We attempted to capture what we believe to be both a reasonable and widely-supported approach to handling AI use, but the very fact that so many authors will face adverse consequences entails that there is complexity in this matter.
Building consensus around the appropriate use of AI will require the development of new norms. The norm we have attempted to implement here is one that holds that the substantial use of AI for writing final submissions imposes a significant cost on the research community: it becomes unclear if an AI-generated text includes only human-generated and human-verified ideas, for which humans will take full responsibility. We believe that in order to justify these costs on an already-strained system, there must be a corresponding benefit to the community. We hold that delegating the writing of the final paper to AI does not offer that benefit.
We thank the community for their sustained interest and engagement in the NeurIPS Position Paper track. We hope these decisions will not only ensure that authors are abiding by stated policy, but also elevate the quality of submissions that reviewers and area chairs will be dedicating time to this year.
Alex Lu, Seth Lazar, David Rugamer
NeurIPS Position Paper Chairs
Stanley Hua, Kate Metcalf
NeurIPS Assistant Position Paper Chairs